 次方量化-技术博客
次方量化-技术博客量化第一课:backtrader实现双均线策略
# -*- coding: utf-8 -*-
"""数据加载模块"""
import pandas as pd
import pymysql
from typing import Optional
# 数据库配置
DB_CONFIG = {
"host": "223.109.142.60",
"port": 3306,
"user": "huayang",
"password": "huayang555",
"database": "etf",
"charset": "utf8mb4"
}
#从数据库拿数据
def read_etf_data(code: str, start: Optional[str] = None, end: Optional[str] = None) -> pd.DataFrame:
sql = "SELECT trade_date as date, open, high, low, close, volume FROM etf_hist_data WHERE code = %s"
params = [code]
if start:
sql += " AND trade_date >= %s"
params.append(start)
if end:
sql += " AND trade_date <= %s"
params.append(end)
sql += " ORDER BY trade_date ASC"
try:
conn = pymysql.connect(**DB_CONFIG)
df = pd.read_sql(sql, conn, params=params)
conn.close()
return df
except Exception as e:
print(f"⚠️ 数据库读取失败 [{code}]: {e}")
return pd.DataFrame()
#转化成bt格式
def load_etf(code: str, start: str, end: str):
df = read_etf_data(code, start, end)
if df.empty or len(df) < 10:
print(f"⚠️ {code} 数据不足")
return None
df['date'] = pd.to_datetime(df['date'])
df = df.dropna(subset=['open', 'high', 'low', 'close', 'volume'])
df.set_index('date', inplace=True)
return df# -*- coding: utf-8 -*-
"""
ETF择时策略回测 - 课程Demo
简单双均线策略:金叉买入,死叉卖出
"""
import backtrader as bt
import warnings
from typing import List
import show_plot
import data_loader
warnings.filterwarnings('ignore')
# ===================== 双均线策略 =====================
class DualMA_Strategy(bt.Strategy):
params = dict(
short_period=10, # 短期均线周期
long_period=30, # 长期均线周期
)
def __init__(self):
# 计算均线
self.short_ma = bt.ind.SMA(self.data.close, period=self.p.short_period)
self.long_ma = bt.ind.SMA(self.data.close, period=self.p.long_period)
self.crossover = bt.ind.CrossOver(self.short_ma, self.long_ma) # 金叉死叉信号
self.holding = False #默认空仓
# 记录净值曲线
self.nav_list: List[float] = []
self.date_list: List[object] = []
def log(self, txt):
print(f'{self.datetime.date()}, {txt}') #打印日期
def next(self):
self.nav_list.append(self.broker.getvalue() / 100000) #初始净值1
self.date_list.append(self.datetime.date())
# 数据不足时跳过
if len(self.data) < self.p.long_period:
return
close = self.data.close[0] #以当天收盘价成交
# 金叉买入
if self.crossover[0] > 0 and not self.holding:
size = int(self.broker.get_cash() * 0.95 / close) #买入数量
if size > 0:
self.buy(size=size)
self.holding = True
self.log(f'买入 ¥ {close:.2f}')
# 死叉卖出
elif self.crossover[0] < 0 and self.holding:
self.close()
self.holding = False
self.log(f'卖出 ¥ {close:.2f}')
# ===================== 配置 =====================
CONFIG = {
'cash': 100000, # 初始资金
'commission': 0.0005, # 手续费
'etf': 'sz159915', # ETF代码 (创业板)
'benchmark': 'sh510300', # 基准ETF (可设为None不显示基准)
'start': '2020-01-01', # 开始日期
'end': '2025-12-31', # 结束日期
}
PARAMS = {
'short_period': 5, # 短期均线
'long_period': 30, # 长期均线
}
# ===================== 主程序 =====================
if __name__ == '__main__':
# 初始化
cerebro = bt.Cerebro()
cerebro.broker.setcash(CONFIG['cash'])
cerebro.broker.setcommission(CONFIG['commission'])
# 加载数据
print("加载数据...")
df = data_loader.load_etf(CONFIG['etf'], CONFIG['start'], CONFIG['end'])
data = bt.feeds.PandasData(dataname=df, name=CONFIG['etf'])
cerebro.adddata(data)
# 添加策略
cerebro.addstrategy(DualMA_Strategy, **PARAMS)
# 添加分析器
cerebro.addanalyzer(bt.analyzers.DrawDown, _name='dd')
# 运行
print("运行回测...")
results = cerebro.run()
strat = results[0]
# 结果
final = cerebro.broker.getvalue() #最终资金
ret = (final - CONFIG['cash']) / CONFIG['cash'] * 100
dd = strat.analyzers.dd.get_analysis()['max']['drawdown']
print("\n" + "=" * 40)
print(f"策略收益: {ret:.2f}%")
print(f"最大回撤: {dd:.2f}%")
print("=" * 40)
# 绘图 (自动加载成交量和基准数据)
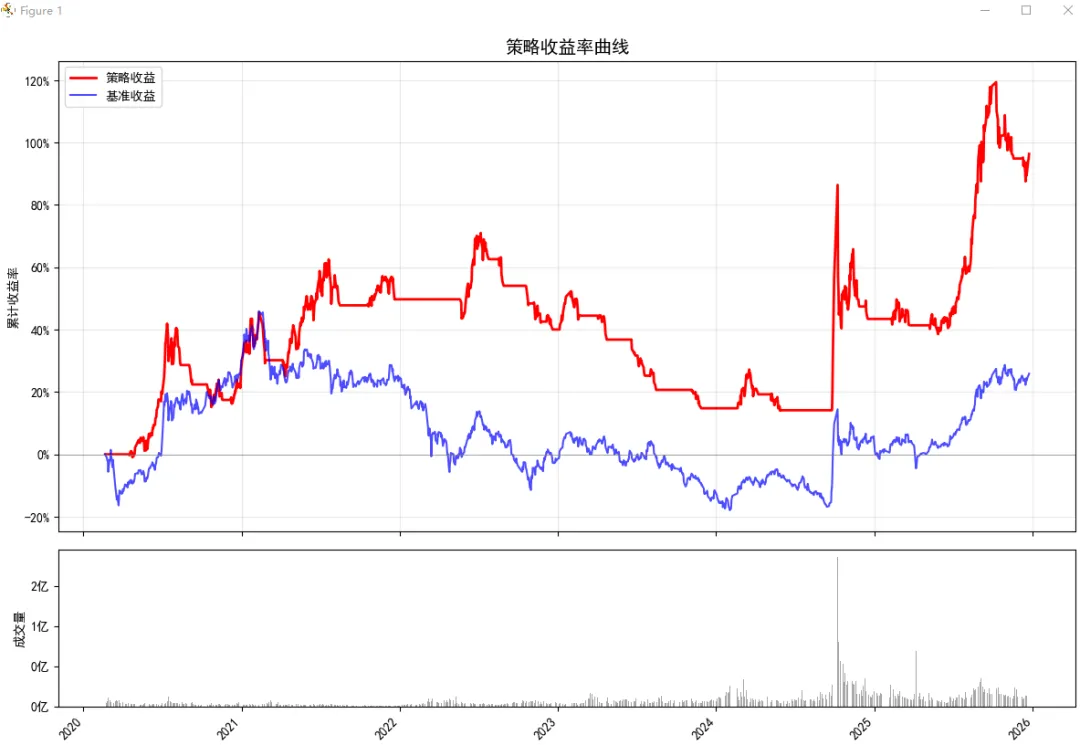
show_plot.plot_return_curve(strat, CONFIG['etf'], CONFIG['start'], CONFIG['end'], CONFIG['benchmark'])【把数据结果可视化:show_plot.py】绘制收益率曲线的时候,也把成交量一起计算上,跟一个ETF做对比。# -*- coding: utf-8 -*-
"""可视化模块"""
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
import data_loader
matplotlib.use('TkAgg')
plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
def plot_return_curve(strategy, etf_code: str, start: str, end: str, bench_code: str = None):
"""
绘制收益率曲线
"""
# 策略数据
df = pd.DataFrame({
'date': pd.to_datetime(strategy.date_list),
'nav': strategy.nav_list
}).drop_duplicates(subset='date', keep='last')
initial = df['nav'].iloc[0]
df['strat_return'] = (df['nav'] - initial) / initial
# 加载成交量
vol_df = data_loader.read_etf_data(etf_code, start, end)
if not vol_df.empty:
vol_df['date'] = pd.to_datetime(vol_df['date'])
df = pd.merge(df, vol_df[['date', 'volume']], on='date', how='left')
# 加载基准数据
if bench_code:
bench_df = data_loader.read_etf_data(bench_code, start, end)
if not bench_df.empty:
bench_df['date'] = pd.to_datetime(bench_df['date'])
bench_df = bench_df.dropna(subset=['close']).sort_values('date')
bench_df['bench_return'] = bench_df['close'] / bench_df['close'].iloc[0] - 1
df = pd.merge(df, bench_df[['date', 'bench_return']], on='date', how='left')
df['bench_return'] = df['bench_return'] - df['bench_return'].iloc[0]
# 绘图
has_vol = 'volume' in df.columns
has_bench = bench_code and 'bench_return' in df.columns
if has_vol:
fig, (ax1, ax2) = plt.subplots(2, 1, figsize=(12, 8), gridspec_kw={'height_ratios': [3, 1]}, sharex=True)
else:
fig, ax1 = plt.subplots(figsize=(12, 6))
# 收益曲线
ax1.plot(df['date'], df['strat_return'], label='策略收益', c='red', lw=2)
if has_bench:
ax1.plot(df['date'], df['bench_return'], label='基准收益', c='blue', lw=1.5, alpha=0.7)
ax1.set_title('策略收益率曲线', fontsize=14)
ax1.set_ylabel('累计收益率')
ax1.legend()
ax1.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{x*100:.0f}%'))
ax1.grid(True, alpha=0.3)
ax1.axhline(y=0, color='gray', lw=0.5)
# 成交量
if has_vol:
ax2.bar(df['date'], df['volume'], color='gray', alpha=0.7)
ax2.set_ylabel('成交量')
ax2.yaxis.set_major_formatter(plt.FuncFormatter(lambda x, _: f'{x/1e8:.0f}亿'))
fig.autofmt_xdate(rotation=45)
plt.tight_layout()
plt.show()

作者文章
- 一文看懂QMT:量化不再是机构的专属 6天前
- ETF动量轮动策略,年化60%回撤14% 4周前 (05-08)
- 2026年 QMT & miniQMT 券商支持清单 2个月前 (04-15)
- 年化191%的策略,我们拆解下,是否过拟合? 5个月前 (01-05)
- 美军直接抓人!委内瑞拉的石油,美国抢定了? 5个月前 (01-05)
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。